


ช่วงปีที่ผ่านมานี้ผมได้มีโอกาสทำ LLM Project จึงอยากนำสิ่งที่ได้เรียนรู้มาฝากกันครับ ประเด็นหลักๆ ที่อยากพูดถึงคือ
- Model Selection: Accuracy before Cost
- Monitoring and Logging for Observerbility and Visibility
- JSON Mode to Structured Outputs and Accuracy
- Prompt Optimization by LLM for LLM
- Few-Shot Prompting
- Agentic Task Breakdown
- Fine-Tune: Agentic Task Breakdown + Logging and Monitoring
Model Selection: Accuracy before Cost
ความท้าทาย
คำถามแรกๆหลังจากที่ได้รับโปรเจคมาคือ “เราจะใช้โมเดลไหนดี”
หากเริ่มคิดถึงคำถามนี้ เราจะสามารถมองได้สองมุมคือ Accuracy vs Cost
ยิ่งโมเดล Accuracy สูง Cost สูง แล้วเราจะจัดลำดับความสำคัญอะไรก่อนดีละ?
บทเรียน
คำตอบคือ เริ่มจาก Accuracy ก่อน!
ทำไมถึงเป็นเช่นนั้นละ? ถ้าลองคิดง่ายๆ คือถ้า Accuracy ไม่ถึง Product มันจะใช้ไม่ได้ ไม่ว่าด้วยราคาเท่าไร คนก็ไม่ใช้ แต่ถ้า Cost แพงเกินแต่ Product ยังใช้ได้ เรายังมีเวลาไป Optimize Cost ลงอีก
คำตอบนี้ค่อนข้างจะตรงกับสิ่งที่ OpenAI แนะนำ
คือ เราควรจะเริ่มจาก Accuracy หรือความแม่นยำก่อนนั่นเอง
นอกจาก จะเลือก Accuracy ก่อนแล้วนั้น เราจำเป็นจะต้องกำหนดนิยามของ “Accuracy Goal” ให้ชัดเจน ว่าสำหรับ Feature ไหนต้องการความแม่นยำกี่เปอร์เซ็น ของ Benchmark(Test Dataset) ไหน
สามารถไปอ่านเพิ่มเติมได้ที่ https://platform.openai.com/docs/guides/model-selection#1-focus-on-accuracy-first
Monitoring and Logging for Observerbility and Visibility
ความท้าทาย
Debug/Accuracy Monitoring
ในการทำงานกับระบบ LLM อย่างเช่น RAG, Chain, Agentic สิ่งที่เจอบ่อยก็คือ “มันพังตรงไหน” “ต้องแก้ตรงไหน” ดังนั้นการเห็นสิ่งที่เกิดขึ้นข้างใน System ถือว่าสำคัญมาก เพื่อที่จะแก้ปัญหา และปรับปรุงระบบให้ดีขึ้น เราจำเป็นต้องรู้ว่า Input แบบไหน ทำให้เกิด Output แบบไหน
ตัวอย่างเช่น
- ถ้าระบบ RAG ของเราเกิดปัญหาผลลพธ์ไม่ตรง เราจำเป็นต้องดูว่า Context ที่ Retrieve มา มีข้อมูลที่เราคาดหวังมั๊ย และข้อมูลที่ไม่อยากได้มีแค่ไหน และขนาดของ Chunk เพียงพอมั๊ย
- สมมติถ้าเรามี Chain ที่ทำหน้าที่ในการ Generate และ Extract Data เป็น JSON จาก Financial Report แล้วผลลัพธ์ที่ได้ออกมาไม่ตรง เราควรเริ่มจากไปดูว่า Generated Report ที่ออกมาจาก API Call แรกเป็นไปตามที่เราต้องการรึเปล่า
- Data Mining เพื่อรวบรวม Preference ไปทำ Evaluation กับ Fine-Tuning
Cost Monitoring
การ Manage Cost สำหรับ LLM ถือว่าสำคัญมากเนื่องจากต้นทุนของการใช้ระบบขึ้นอยู่กับปริมาณ Input and Output Token ถ้าเราเก็บตัวเลขพวกนี้ไว้ เราจะสามารถเอาไว้ตอบ stakeholder ต่างๆได้ว่า Feature ไหนใช้ต้นทุนเท่าไรแล้วเราควร Optimize ตรงไหน
Distillation
นอกจากการ Monitoring ด้วยจุดประสงค์ด้านบนแล้วสิ่งที่เป็นประโยชน์คือการเก็บผลลัพธ์ที่ต้องการ เพื่อนำไป Fine-tune ต่อให้กับโมเดลเดิมหรือ Distillation ให้กับโมเดลที่เล็กกว่าก็มีความสำคัญใน Optimization Phase เช่นกัน
บทเรียน
ทางแก้ก็คือ Set Up Tools ที่ช่วยเรื่อง Monitoring and Logging ที่ออกแบบมาเพื่อ LLM project โดยเฉพาะ
Tools ในตลาดที่มีให้เห็นตอนนี้คือ
- LangSmith
- LangFuse
- Build-In Stored Completion ของ OpenAI Model Distillation(https://openai.com/index/api-model-distillation/) หรือ Azure Foundry Model Distillation https://techcommunity.microsoft.com/blog/azure-ai-services-blog/introducing-model-distillation-in-azure-openai-service/4298627
JSON Mode to Structured Outputs and Accuracy Drop
หมายเหตุ: ต้องอธิบายก่อนไปต่อว่า ณ ปัจจุบัน OpenAI มี Feature ที่ช่วยในการบังคับ Output ออกมาเป็น JSON 2 ทางเลือกดังนี้:
- JSON Mode
- Structured Outputs(Newer — Release August 2024)
JSON Mode คือ feature ที่มีมาก่อน Structured Outputs ซึ่งเจ้า JSON Mode เนี่ยจะรับประกันว่า Output ที่ได้ออกมาคือ Valid JSON แต่ว่าไม่ได้รับประกัน Schema ในขณะที่ Structured Outputs รับประกันว่า Output จะรับประกันทั้ง Valid JSON กับ ตัว Schema ด้วย
ณ ปัจจุบันทาง OpenAI ก็แนะนำให้ใช้ตัว Structured Outputs เป็นหลักแล้วครับ
ความท้าทาย
JSON — Structured Outputs is not the same as freely answer outputs
ในการทำ LLM ที่เอาไปใส่ไว้ใน Backend โดยส่วนใหญ่ ถ้าไม่ได้เป็น Chat แต่เป็นแนว Automation Workflow หรือ Agentic AI ตัว LLM มักจะต้อง Output ออกมาเป็น JSON เพื่อความง่ายในการ Integrate กับระบบอื่นๆ
สิ่งที่ได้เรียนรู้จากให้ LLM Output ออกมาเป็น JSON คือความแม่นยำและประสิทธิภาพการทำงานจะลดลงถ้าไปบังคับรูปแบบของ Output ออกมามากๆ ซึ่งบทเรียนตรงนี้ ตอนหลังพบว่ามีงานวิจัยออกมายืนยันเหมือนกัน Let Me Speak Freely? A Study on the Impact of Format Restrictions on Performance of Large Language Models
บทเรียน
สำหรับปัญหา Accuracy ตก ไม่ว่าจากงานที่ซับซ้อนหรือจากการบังคับ Output JSON มีวิธีแก้หลักๆ ที่ผมแนะนำอยู่ 3 ทาง(โดยที่ไม่ต้อง Fine-Tune)
- Prompt Optimization by LLM for LLM
- Few-Shot Prompting
- Agentic Task Breakdown
- Fine-Tune: Agentic Task Breakdown + Logging and Monitoring
Prompt Optimization by LLM for LLM
หนึ่งในเทคนิคที่เพิ่ม accuracy ได้ง่าย และมีประสิทธิภาพรวดเร็วที่สุดคือ การให้ LLM เขียน Prompt ให้เรา ง่ายมากๆ เพียงแค่เอา Prompt เราเขียนได้ ส่งให้ Chatbot ปรับปรุงอีกรอบ แล้วเอามาใช้ได้เลย
จากการทดลองพบว่า ควรใช้ Model ที่จะเอาไปใช้งานด้วยเป็นคนปรับปรุง Prompt เอง
ตัวอย่างเช่น
ถ้า Prompt ที่จะเขียนจะถูกเอาไปใช้กับ Model GPT-4o ก็ควรใช้ GPT-4o ในการปรับปรุง Prompt
Prompt ที่ผมใช้คือ
Please improve this LLM instruction
Instruction:[Your initial prompt here]
วิธีนี้เหมาะเป็นอย่างยิ่งและควรนำไปเป็น Practice หรือหลักปฎิบัติสำหรับทีมที่ไม่ได้เป็น Native English Speaker/Writer จะช่วยป้องกันข้อผิดพลาดได้เป็นอย่างมาก
สำหรับคนที่อยากได้ Prompt ที่ละเอียดกว่านี้ ดีกว่านี้แนะนำไปดูต่อที่
Few-Shot Prompting
หนึ่งในเทคนิค Prompt Engineering ที่ผมคิดว่ามีประโยชน์ที่สุดในการทำ LLM project ต้องยกให้เป็น Few-Shot Prompting เลยครับ คือเทคนิคนี้ช่วยชีวิตไว้หลายรอบมาก
อธิบายง่ายๆ Few-Shot prompt คือการให้ตัวอย่าง Input/Output ไปใน Prompt เพื่อเป็น guideline ให้ตัว LLM ตอบตามที่เราต้องการ
Style ในการเขียน Few-Shot prompt จริงๆ มี 2 แบบที่ทำกันคือ Naive และ Stricted(ผมคิดชื่อให้มันเอง)
- Naive: แปะตัวอย่างไว้ใน Prompt เดียวกับ Instruction เลย
- Multi-Turn: แปะตัวอย่างไว้ใน messages property array ของ SDK เลย(พบว่าแบบนี้ง่ายและแม่นยำมากกว่า และบังคับให้เราใส่ ตัวอย่าง Input/Output ด้วย)
ตัวอย่างเช่น
Naive
async function main() {
const chatCompletion = await client.chat.completions.create({
messages: [{ role: 'user', content: `Write a summary of a given text
Text: [Input Text Example 1]
Output: [Output Text Example 1]
Text: [Input Text Example 2]
Output: [Output Text Example 2]
Output:`}],
model: 'gpt-4o',
});
}
Multi-Turn
async function main() {const chatCompletion = await client.chat.completions.create({messages: [{ role: 'system', content: `Write a summary of a given text`},{role: 'user', content: `[Input Text Example 1]`},{role: 'assistant', content: `[Output Text Example 1]`},{role: 'user', content: `[Input Text Example 2]`},{role: 'assistant', content: `[Output Text Example 2]`},{role: 'user', content: `[Input Text Example 3]`},{role: 'assistant', content: `[Output Text Example 3]`}],model: 'gpt-4o',});}
เคสที่มีประโยชน์มากสำหรับ Few-shots prompt คือตอนที่เราต้องการให้ Model Output ออกมามี Schema ที่แปลกๆ หรือซับซ้อน
จากที่พูดถึงด้านบนคือเรามี Structured Output แล้วแต่ว่าบางทีอาจจะยังไม่ถูกใจ การเพิ่ม Few-shots prompt ให้ LLM ไปดูเป็นตัวอย่างด้วยจะช่วยเพิ่มความแม่นยำได้มากขึ้น
สำหรับจำนวนตัวอย่าง ผมแนะนำให้ทำ 3 ตัวอย่างขึ้นไป แล้วลองดูคำตอบเอาว่าดีพอรึยัง ถ้าเพิ่มขึ้นเรื่อยๆ แล้วยังไม่ได้ ให้ ลอง Agentic Task Breakdown ดู
Agentic Task Breakdown
ความจริงข้อนึงที่ค้นพบคือ ยิ่งเราให้ LLM ทำงานยากเท่าไรความแม่นยำและประสิทธิภาพจะยิ่งลดลงมากขึ้นเท่านั้น การแบ่งความรับผิดชอบออกเป็นส่วนๆจะช่วยให้เราแก้ปัญหาได้ทีละส่วน เพิ่มความแม่นยำทีละส่วน หรือที่ผมเรียกว่า Agentic Task Breakdown นั่นเอง
ลองดู Diagram การใช้งาน หรือ การเรียก LLM Agent เบื้องต้น ดังนี้
- Input: Input ที่ได้รับจาก User
- LLM Agent: LLM inference หรือการเรียก LLM API ธรรมดา
- Output: Output ที่ได้ออกมาจาก LLM API
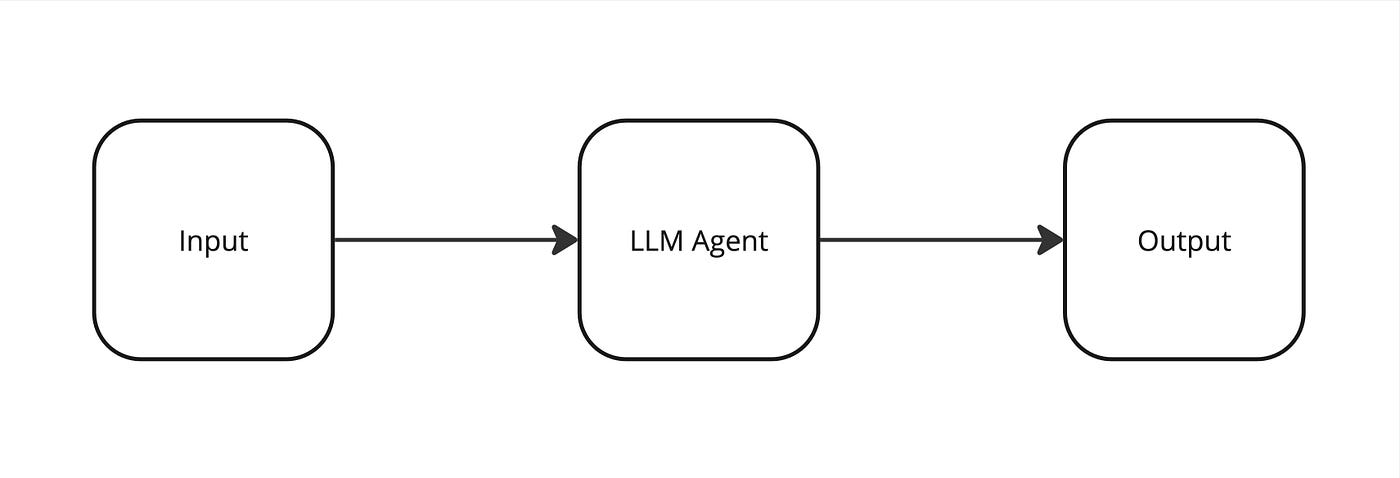
ถ้าเรานำรูปแบบการเรียกใช้งานไปใช้ ตัวอย่างเช่น
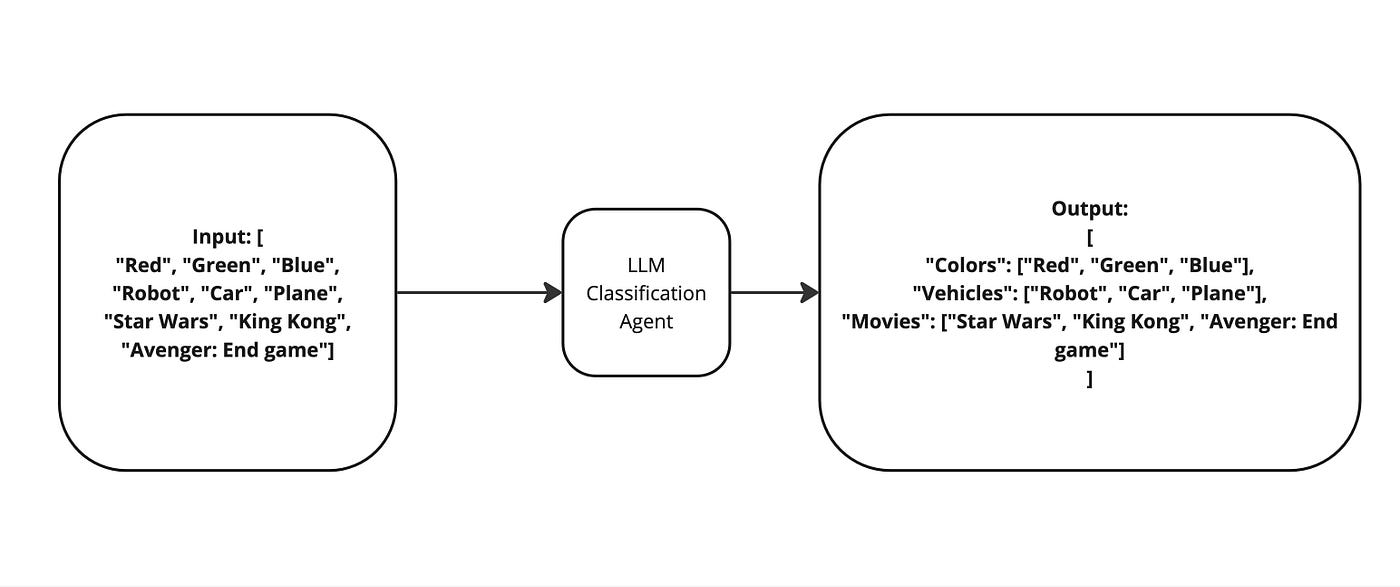
Classification Task: ถ้าเราให้ LLM ทำงาน Classification Task สำหรับ Input เป็น array of string ที่มีขนาด 5 ตัว มีแนวโน้มจะมีความแม่นยำมากกว่า Task สำหรับ Input เป็น array of string ที่มีขนาด 40 ตัว บางที่ Output ที่ต้องการให้ Classify อาจจะหายไป 2–3 ตัวก็ได้(ดูตัวอย่างจาก Diagram)
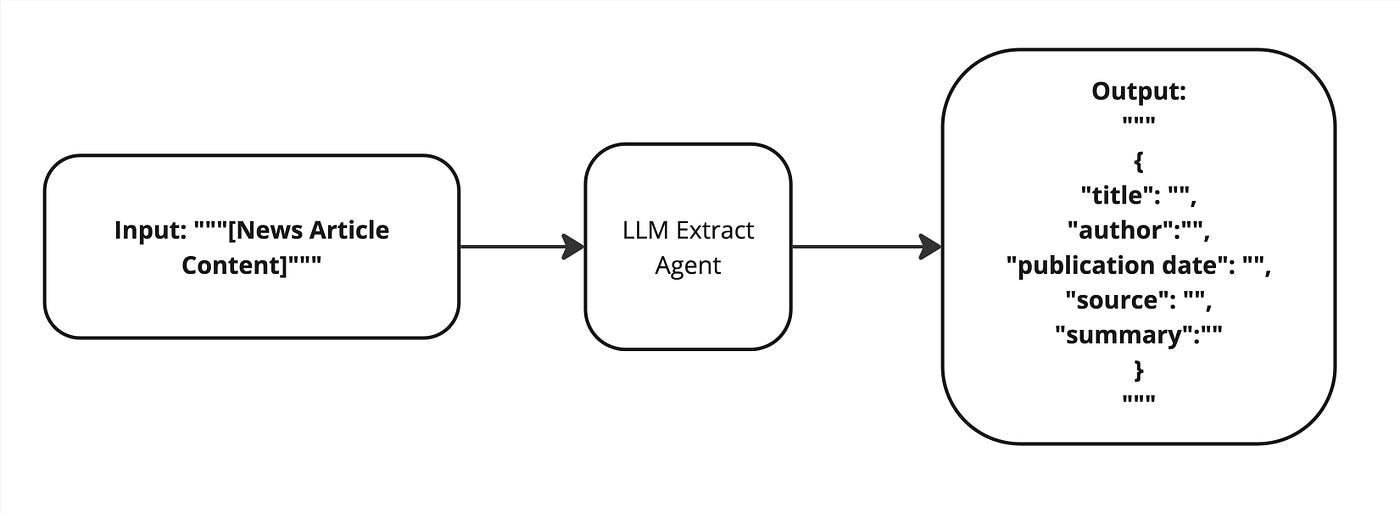
Extract Data Task: ถ้าเราให้ LLM ทำงาน Extract Data จาก Business Report โดยข้อมูลที่ต้องการให้ Extract มี 5 Fields มีแนวโน้มจะมีความแม่นยำในการ Extract มากกว่า Task ที่ให้ Extract 20 Fields(ดูตัวอย่างจาก Diagram)
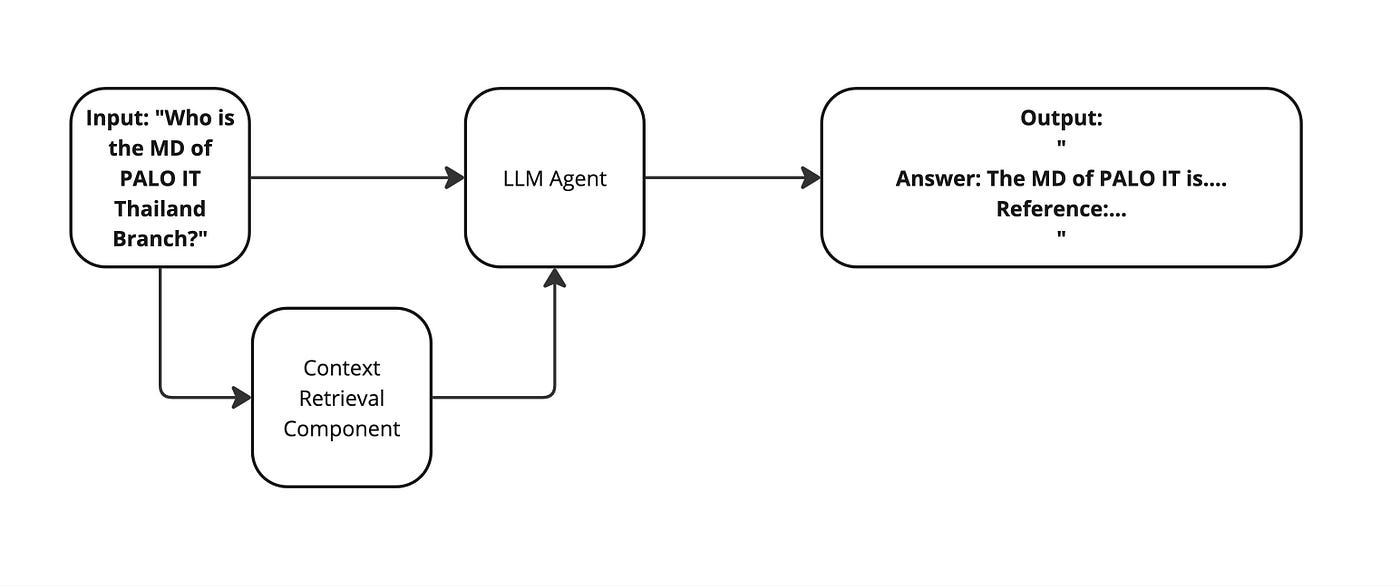
Enterprise RAG Chatbot: จากตัวอย่างทั้งสองด้านบน ในชีวิตจริงความต้องการทางธุรกิจจะทำให้ความซับซ้อนมากขึ้นไปอีก จากความต้องการในการเพิ่มและดัดแปลง style และความละเอียดในการตอบ จึงอยากยกตัวอย่าง Enterpirse RAG Chatbot ที่กำลังถูกบุกเบิกอยู่ใน PALO IT
ทางออกของปัญหานี้คือ
แบ่งความซับซ้อน หรือ ปัญหาออกเป็นส่วนๆ ใช้ AI Agent ตัวนึงในการ ทำงานเพียงแค่อย่างเดียว จากตัวอย่างข้างต้นเราสามารถแก้ได้โดยแบ่งการเรียกออกเป็นส่วนๆ Patter ที่จะนำเสนอคือนอกจาก Agent ที่ทำ Task จะมีการเพิ่ม Agent ตัวอื่นที่จำเป็นเพิ่มขึ้นไปอีก สามารถดู Diagram ตามด้านล่างได้เลย
Agentic Classification Task
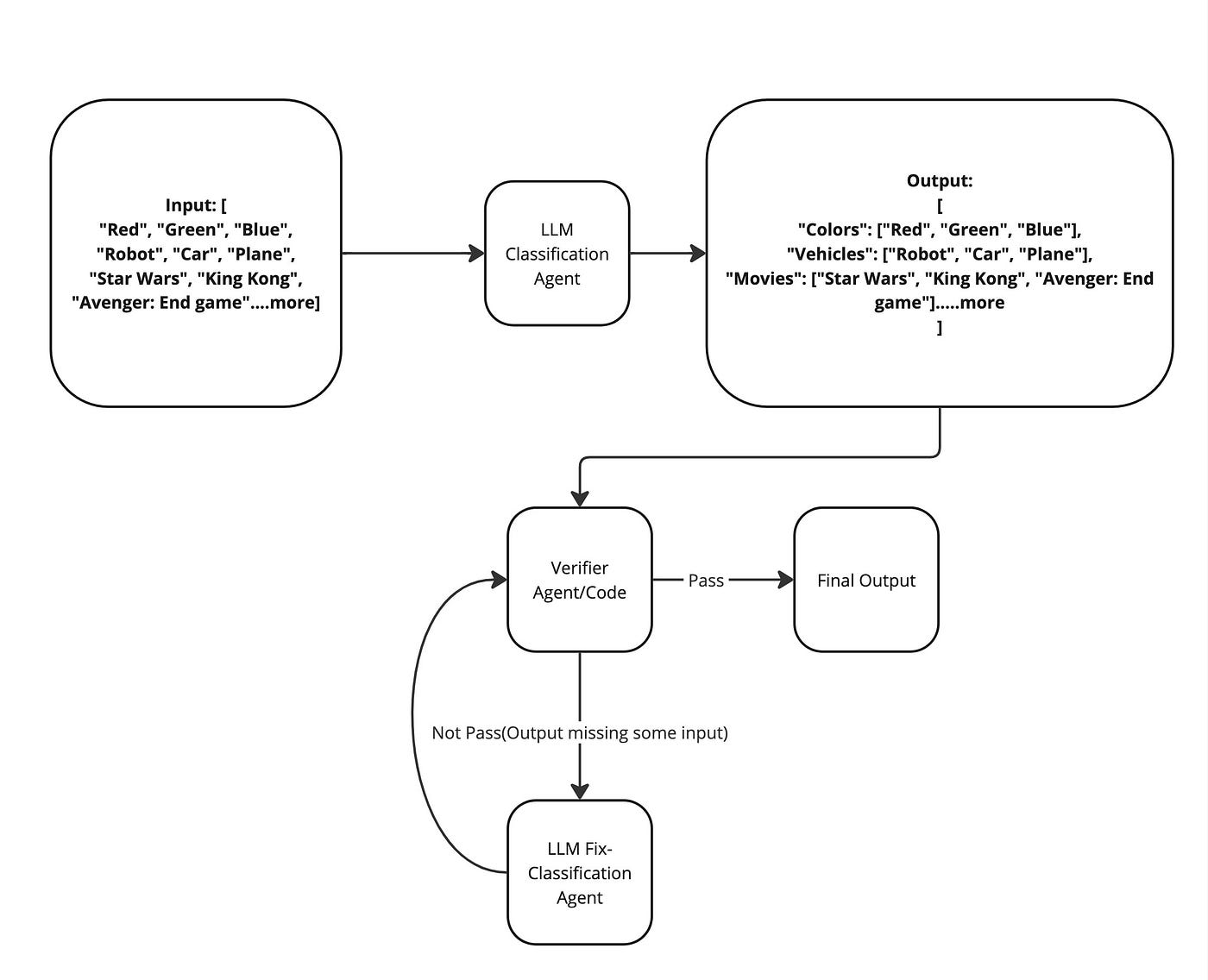
คำอธิบาย
Diagram นี้ได้เพิ่ม Verifier Agent/Code เพื่อตรวจสอบความถูกต้องว่ามี Output อันไหนขาดไปมั๊ย หากครบแล้ว ก็จะส่งไป Final Output เลย ถ้ายังขาดจะส่ง Input ที่ยังไม่ได้ Classify ไปยัง LLM Fix-Classification Agent จะเห็นได้ว่า Agent ทั้งสามตัวแบ่งงานกันทำคนละอย่าง ดังนี้
- Generate คำตอบเบื้องต้น
- ตรวจสอบผลลัพธ์
- แก้ไขผลลัพธ์
Agentic Extract Data Task
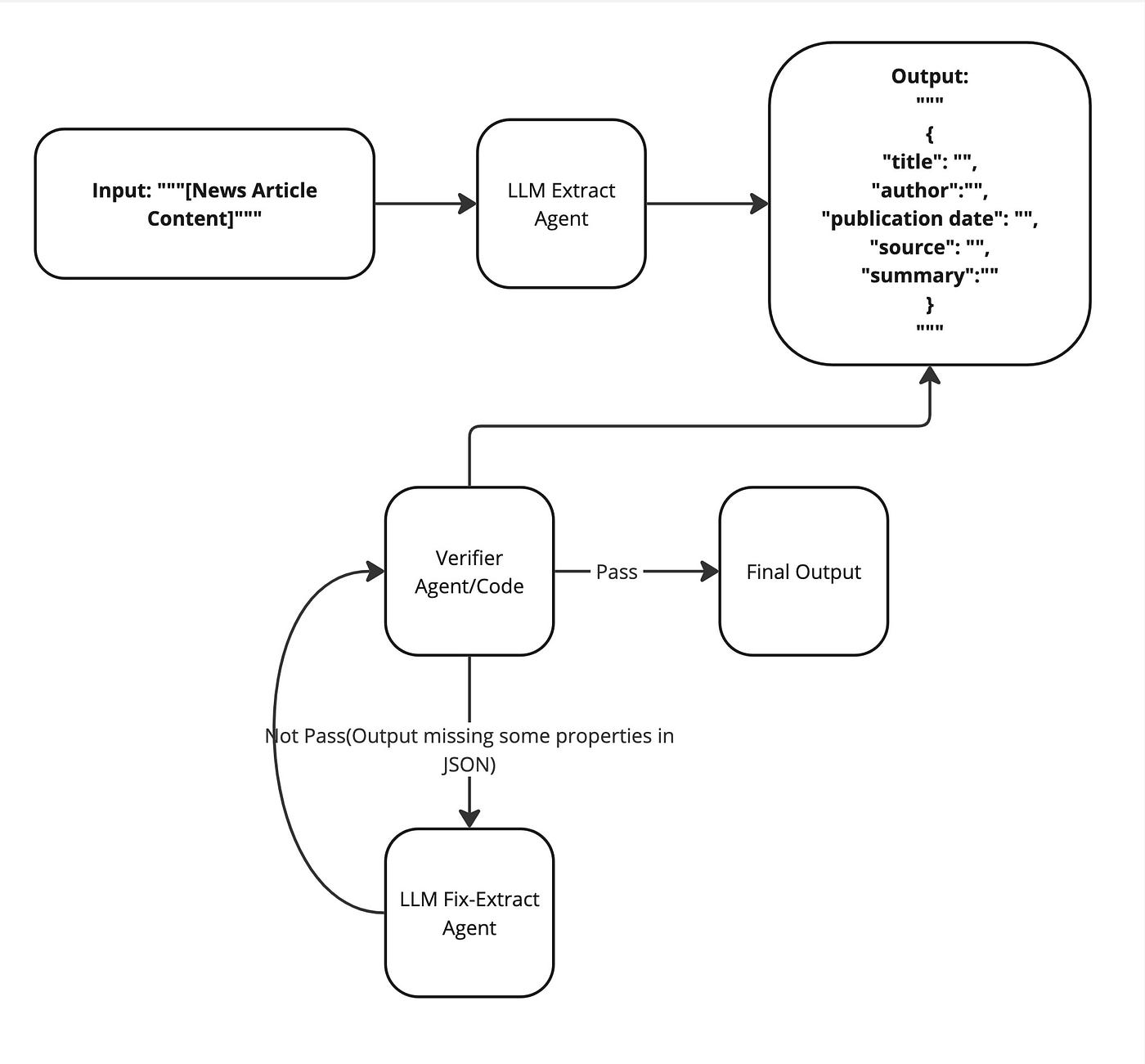
คำอธิบาย
Diagram นี้ได้ เพิ่ม Verifier Agent/Code เพื่อตรวจสอบความถูกต้องว่ามี Output อันไหนขาดไปมั๊ย หากครบแล้ว ก็จะส่งไป Final Output เลย ถ้ายังขาดจะส่ง Input ที่ยังไม่ได้ Classify ไปยัง LLM Fix-Extract Agent จะเห็นได้ว่า Agent ทั้งสามตัวแบ่งงานกันทำคนละอย่าง ดังนี้
- Generate คำตอบเบื้องต้น
- ตรวจสอบผลลัพธ์
- แก้ไขผลลัพธ์
Agentic Enterprise RAG Chatbot
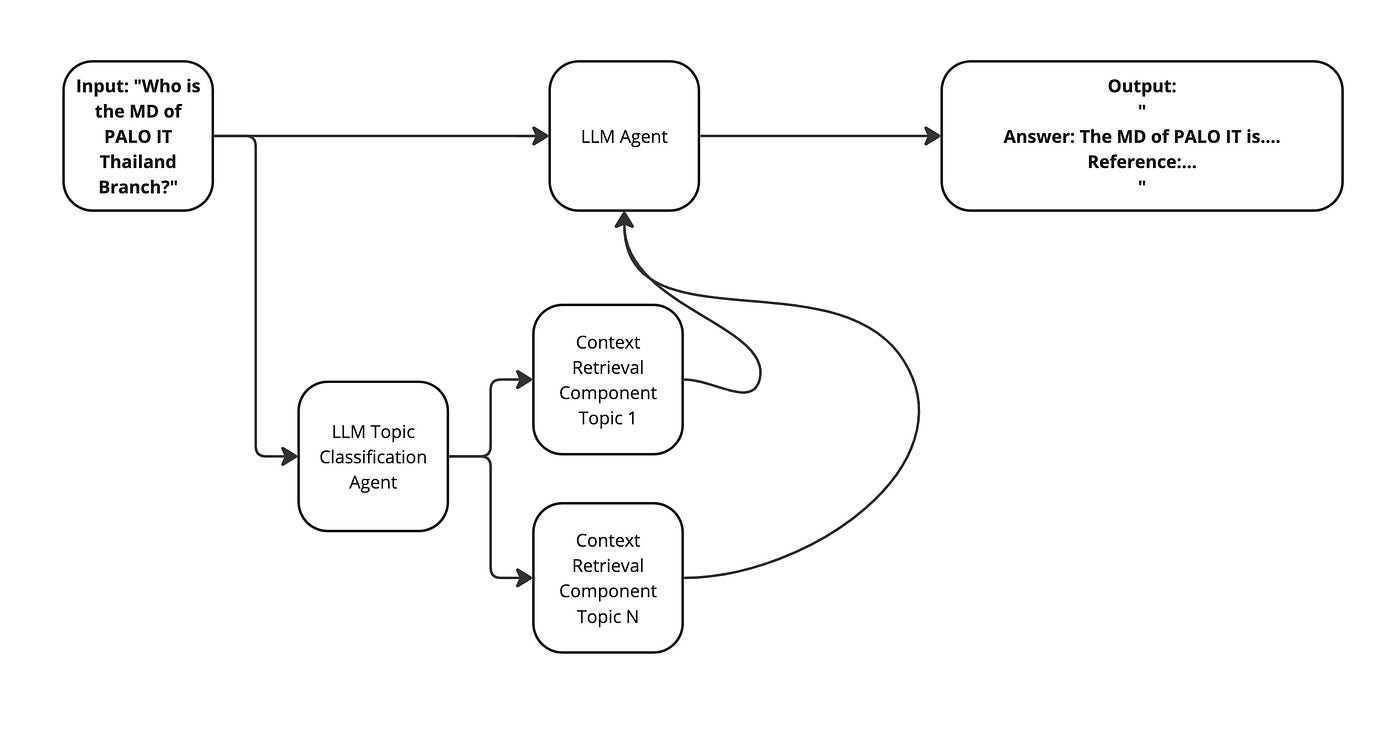
คำอธิบาย
Diagram นี้ได้เพิ่ม LLM Topic Classification Agent ขึ้นมาเพื่อช่วย LLM Agent ตัวหลักที่ใช้ตอบคำถามให้ได้ Context Retrieval ที่แม่นยำ หรือเกี่ยวข้องกับคำถามมากขึ้น ก่อนนำมาตอบคำถามจะเห็นได้ว่า Agent ทั้งสองตัวแบ่งงานกันทำคนละอย่าง ดังนี้
- เลือกหัวข้อที่เกี่ยวข้อง
- Generate คำตอบเบื้องต้น
สำหรับ RAG Best Practice แนะนำให้ไปอ่านได้ที่งานวิจัยนี้ครับ Searching for Best Practices in Retrieval-Augmented Generation
สำหรับการสร้าง Agentic AI ผมแนะนำให้ไปอ่านเพิ่มเติมที่ https://www.anthropic.com/research/building-effective-agents
Fine-Tune: Agentic Task Breakdown + Logging and Monitoring
จากที่พูดถึงมาใน section ของ Logging and Monitoring และ Agentic Task Breakdown แน่นอนว่าถ้านำผลลัพธ์ของ Agentic Task Break Down ที่แม่นยำจากการ Call Agent 2–3 ตัว จะทำให้ Cost เพิ่มขึ้นอย่างแน่นอน
วิธีการ Optimize Cost ก็คือ การนำผลลัพธ์สุดท้ายของ Agents ที่ตรวจสอบแล้ว ไม่ว่าจะด้วย LLM-as-a-Judge หรือ Human Evaluation ไปเก็บไว้เป็น Dataset เราก็สามารถนำไป Fine-Tune ได้
ในทางทฤษฎี วิธีการนี้จะสามารถลด Cost ได้เพราะ Model หลังจาก Fine-Tune แล้วจะสามารถทำงานได้ดีใกล้เคียงกับ Agent 2–3 ตัว โดยที่ใช้การ Call Agent แค่ครั้งเดียว หรือเรียกง่ายๆ คือเราสามารถสลับกลับไปใช้ Diagram “Classic Agent Call/Inference” ได้
ตัวอย่างเช่น
ตามรูปด้านล่างนี้ลูกศรสีดำชี้ให้เห็นว่าเราควรเก็บ Data ตรงไหนเพื่อนำไปใช้ในการ Distillation/Fine-Tuning
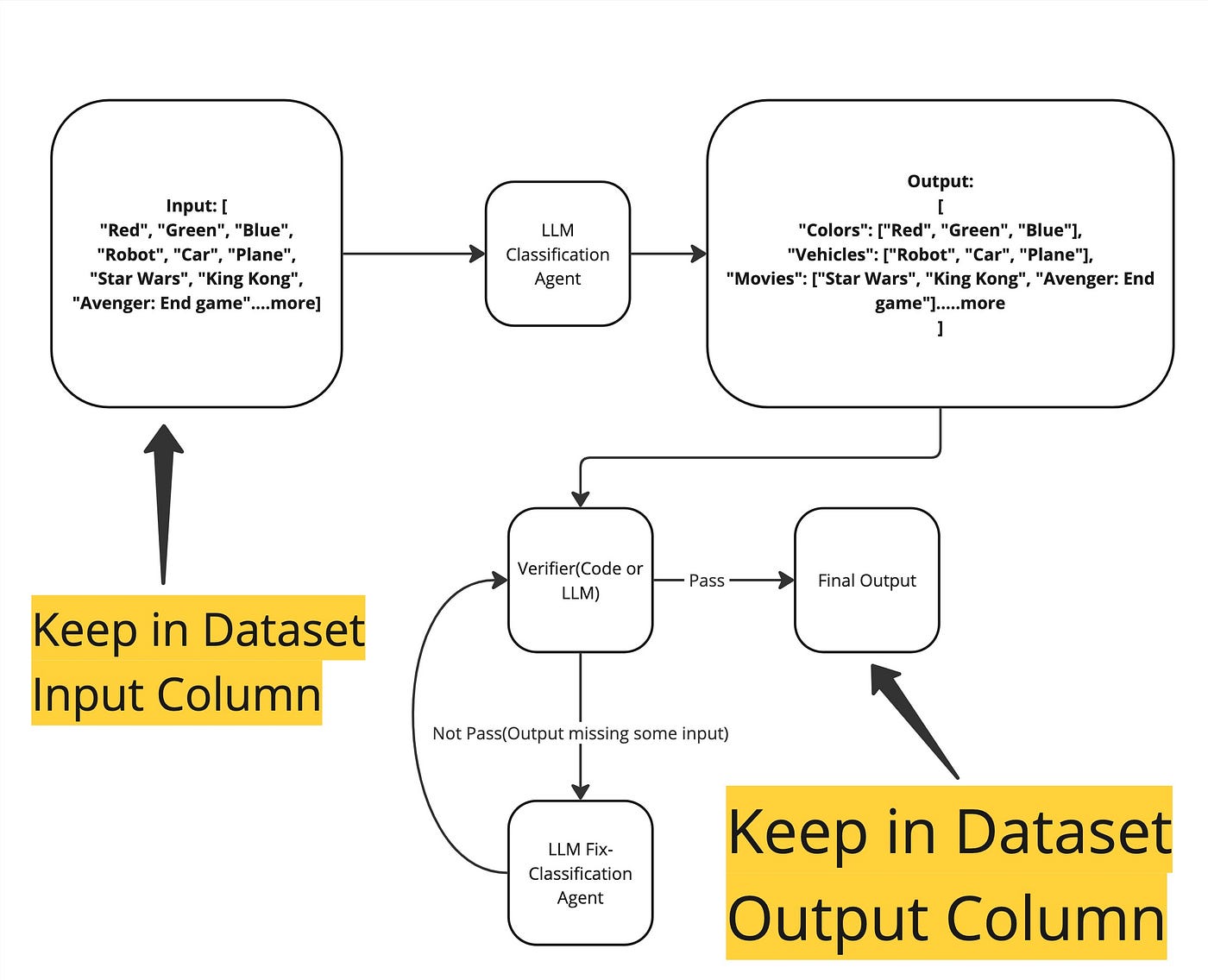
จุดที่เราเก็บ Output คือ Final Output ที่ได้รับการ Verify ความถูกต้องและได้รับการ Fix จาก “LLM Fix-Classification Agent” แล้ว จะเห็นได้ว่า Data ที่เก็บได้น่าจะ “ดีขึ้น” หรือ “ดีพอ” จะนำไป Fine-Tune ได้หาก มี Input ที่หลากหลายทางขนาด และ เนื้อหา มากพอ
บทสรุป
สิ่งที่พอจะสรุปได้จากบทเรียนที่ผ่านมาคือ เราควรกำหนดทิศทางของทีมให้สร้าง Accuracy Goal ที่ทุก Stakeholder พอใจและทุ่มเทเวลาไปกับการปรับ Prompt และ Agentic Breakdown ให้ได้ผลลัพธ์ที่ดีที่สุด
จากนั้นหากได้ผลลัพธ์ที่ผ่านเกณฑ์ที่ตกลงกันไว้แล้วลองไปดูเรื่องของการ Fine-Tune ว่ายังจำเป็นหรือไม่ คุ้มค่าหรือเปล่า
ติดตาม PALO IT ได้ที่
Facebook: https://www.facebook.com/PALOITTH
LinkedIn: https://www.linkedin.com/company/2452379
YouTube: https://www.youtube.com/@PALOITThailand
Website: https://www.palo-it.com


