

.png)
Le machine learning, ou intelligence artificielle, oriente des décisions qui impactent notre quotidien à tous, sans que l’on en prenne forcément conscience. Les applications s’étendent à de nombreux secteurs tels que les loisirs avec des recommandations de musiques ou de films, mais aussi l’achat de produits sur des sites marchands. D’autres domaines ayant des conséquences plus lourdes sur nos vies y ont aussi recours, comme par exemple, le diagnostic médical et les services prêts bancaires.
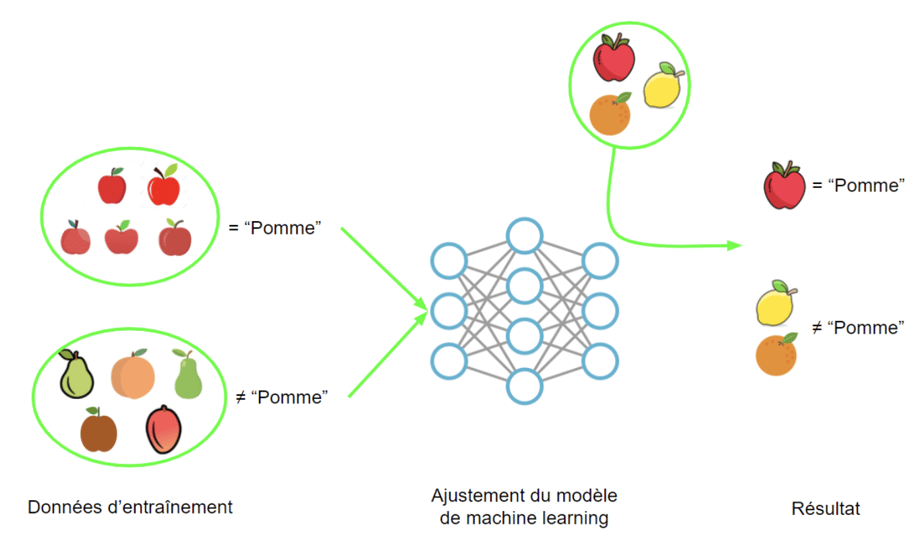
La spécificité de cette technologie est de s’appuyer sur les données, plutôt que sur des modèles conçus par des experts du domaine.
L’algorithme apprend des comportements en lisant des quantités importantes de données, optimisant ainsi un modèle interne, en lieu et place des modèles conçus par les experts. Une fois cette phase d’entraînement terminée , il peut ensuite fournir un résultat sur les nouvelles données qui lui sont proposées.
Cette spécificité lui procure l’avantage considérable d’arriver à reproduire des comportements complexes, difficilement modélisables par les experts. En reconnaissance d’images par exemple, le machine learning a surpassé en performance les meilleurs algorithmes d’analyse d’images.
Cependant, le revers de la médaille est qu’une grande partie de ces algorithmes - ou modèles - de machine learning sont particulièrement opaques : ils reposent sur des centaines voire des milliers de variables intermédiaires, dont la valeur est le résultat d’un processus d’optimisation complexe non compréhensible par un humain.
Étant donné l’importance que prennent les algorithmes de machine learning dans nos vies, il devient capital d’arriver à mieux comprendre leurs comportements, leurs biais et leurs limites. C’est l’objectif de la discipline assez récente qu’est l’explicabilité du machine learning, souvent appelé eXplainable AI pour Intelligence artificielle explicable. Cette discipline, au croisement des sciences sociales, de l’interaction homme-machine et de l’intelligence artificielle vise à donner plus de transparence aux algorithmes de machine learning.
En a-t-on vraiment besoin ?
“Si ça marche, c’est déjà bien non ?” Et bien justement non ! De nombreux exemples de dérives du machine learning ont déjà défrayé la chronique:
- En 2015, un algorithme de Google de labellisation d’image a classifié une photo de personnes noires dans la catégorie gorilles.
- De 2014 à 2018, le système de tri des candidatures d’Amazon reproduisait un biais des recrutements passés et réduisait les chances des femmes de passer un entretien.
- Depuis 1998, le logiciel COMPAS est utilisé par le système judiciaire américain pour prédire la probabilité de récidive et a été dénoncé comme discriminant pour les populations noires, alors que la couleur de peau ne fait pas partie des 130 critères utilisés par l’algorithme.
D’un point de vue moins sensationnel, pour de nombreuses applications, il est capital de pouvoir expliquer les raisons d’une prédiction d’un système de machine learning. Par exemple:
- Pour un système d’évaluation de demandes de prêts bancaires, il est nécessaire d’être capable d’expliquer à un client pourquoi son prêt a été refusé.
- Pour un système de diagnostic automatique : il vaut mieux être capable d’expliquer pourquoi un patient doit se lancer dans un traitement.
Qu’est-ce que l’explicabilité ?
L’explicabilité, en anglais explainability ou eXplainable AI (XAI), est la discipline à l’intersection des sciences sociales et de l’IA qui cherche à rendre les modèles de machine learning plus transparents. Cette discipline fournit des outils techniques et des recommandations pour rendre les algorithmes de machine learning plus compréhensibles pour l’humain.
L’explicabilité a de nombreux usages en fonction des profils :
- Pour un data-scientist : débugger, challenger le modèle et en améliorer les performances.
- Pour les utilisateurs : permettre de comprendre les décisions du système, notamment celles qui ont un impact sur eux, ce qui favorisera son adoption.
- Pour le régulateur : permettre l’auditabilité du système et donc respecter les réglementations (RGPD)
- Pour les entrepreneurs : rassurer sur la pertinence du modèle et son alignement avec la stratégie business.
Comment composer une bonne explication ?
L’explicabilité consiste à justifier un résultat. Cette justification s’adressant à une personne, il est important de garder plusieurs choses en tête lorsque l’on conçoit un système qui vise à expliquer un résultat ou un modèle.
Tim Miller, en s’appuyant sur les connaissances de la psychologie humaine, donne dans son article de 2017 quelques bonnes pratiques pour concevoir de bonnes explications :
- S’appuyer sur des contrastes, c'est-à-dire indiquer pourquoi cette prédiction plutôt qu’une autre ? Par exemple, dans le cas d’un refus de crédit : utiliser une comparaison avec un dossier similaire mais pour lequel le crédit a été accepté.
- Sélectionner, donc privilégier les 1 ou 2 principales causes de la décision. Par exemple, identifier les deux critères principaux qui sont la cause du refus.
- S’adapter au public en fonction du profil, et dans le cas d’un crédit, il s’agit de retrouver un discours sur les données renseignées par le demandeur plutôt qu’à des valeurs de risques.
- Se focaliser sur l’anormal, y-a-t’il une cause rare qui a provoqué un changement important dans la décision ?
- Plus une explication est généralisable à plusieurs individus et probable (intuitivement logique), mieux elle sera reçue.
Pour se persuader de l’intérêt de ces recommandations, il suffit de regarder la manière dont les GAFA fournissent des explications à leurs systèmes de recommandations. “Ceux qui ont acheté X ont aussi acheté Y”, “Car vous connaissez X”, “Car vous avez regardé X” sont autant d’explications qui font appel à l’intuition de l’utilisateur du service, qui se limitent à un nombre très restreint de justifications et qui sont adaptées au public.
Cet article a été imaginé et réalisé par Thibaut Chataing, Yoann Couble et Camille Ponthus.
Rendez-vous prochainement pour la partie 2 !


