


Across numerous industries, professionals grapple with extensive volumes of information housed within a multitude of PDF documents—ranging from invoices and contracts to legal documents and medical records. These documents hold critical data, insights, and references. However, pinpointing specific content or synthesizing information across these PDFs remains a challenging and labor-intensive endeavor. Conventional search methods fall short in extracting meaningful responses or summaries, particularly when contextual understanding across multiple documents is essential.
Generative AI stands poised to revolutionize document management. By extracting information from unstructured or semi-structured documents, recognizing patterns, and analyzing data, it streamlines and optimizes document-based workflows with innovative precision.
According to Gartner, by 2026, the adoption of Gen AI will enable workflow tools and agents to enhance efficiencies for 20% of knowledge workers, a significant increase from less than 1% today.
In this article, we delve into how PALO IT is pioneering an intelligent document processing system using Retrieval-Augmented Generation (RAG).
Objectives of the Document AI:
- Efficiently retrieve and synthesize relevant information from multiple PDF documents.
- Enable users to quickly obtain accurate and contextually meaningful responses or summaries.
- Streamline the process of information extraction and reduce manual search efforts.
- Improve decision-making across various domains such as legal, academic, technical, and business environments.
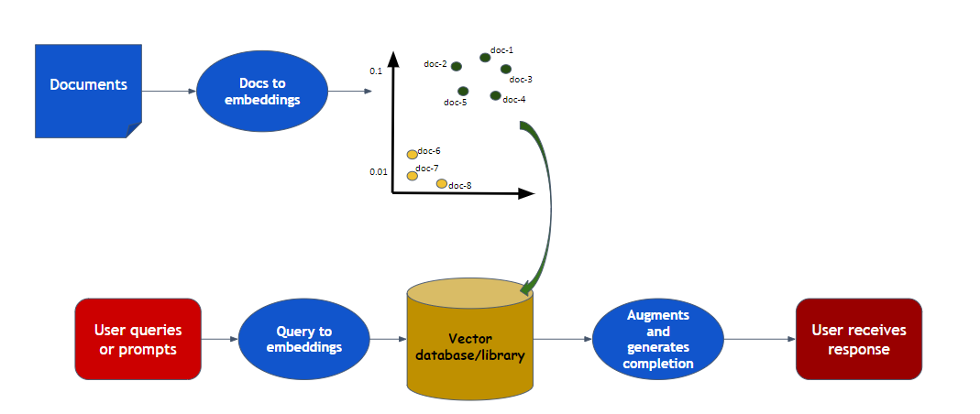
How the multi-document processing system works:
Indexing
1. Load: First, we need to load our data. This is done with Document Loaders.
2. Split: Text splitters break large Documents into smaller chunks. This is useful both for indexing data and for passing it in to a model, since large chunks are harder to search over and won't fit in a model's finite context window.
3. Store: We need somewhere to store and index our splits, so that they can later be searched over. This is often done using a VectorStore and Embeddings model.
Retrieval and generation
4. Retrieve: Given a user input, relevant splits are retrieved from storage using a Retriever.
5. Generate: A ChatModel / LLM produces an answer using a prompt that includes the question and the retrieved data.
Architecture
Product Demo
Product Report
The multi-document PDF Retrieval Augmented Generation system (RAG) offers an innovative solution for professionals across various industries who need to quickly access and synthesize information from multiple PDF documents. By leveraging advanced machine learning techniques for document retrieval and text generation, the system improves productivity and decision-making while reducing the manual effort required to search for information. With further refinement and expansion, the system has the potential to transform how information is accessed and utilized in document-heavy industries.
Is your business seeking to enhance efficiency by reducing manual processes?


