


In this article, I’ll be demonstrating my workflow to get started on a project — by setting up an AWS EMR Cluster using a Cloudformation template.
I’ll first introduce both the Spark app and the Cloudformation template I’ll be using.
I’ll then deploy my demonstration Spark app’s Assembly Jar to an S3 bucket, before running the app on the EMR cluster. Finally, I’ll query the Hive external table created on the cluster using Hue.
As a managed service, I find EMR to be a great option to spin up a cluster to get started right away — and it provides powerful computing functionality, as well as flexible storage options.
Before I go on, I’ll list down the dependencies that I need before I can continue —
* AWS account with root access (preferably)
* IDE and Unix Terminal
* The AWS EMR Pricing guide! — to determine the most cost-effective region to host my EMR cluster.
About the Spark App
For this blog post, I’ll use my simple demonstration app hosted on Github at simple-spark-project, which will -
* Read in an apache web server log file into an RDD[String]structure
* Define a schema, and convert the above RDD[String] into a DataFrame
* Create temp view and then an External Hive Table to be stored in an S3 bucket
The app takes in 3 input parameters -
* S3 URL of the apache web server log file
* S3 URL of the output S3 bucket
* The spark.master configuration (which will be ‘local’ in this example)
The build configuration file in the project defines the libraryDependenciesand the assemblyMergeStrategy to build the Assembly/Uber Jar — which is what will be executed on the EMR cluster.
Build Infrastructure Using Cloudformation
The Cloudformation template I’ll use defines and configures -
* IAM Roles to deploy and read to/from S3 buckets
* IAM Users to read to/from S3 buckets
* 3 x S3 buckets to host the Assembly Jar, Hive external table and the EMR Cluster log
* The EMR Cluster
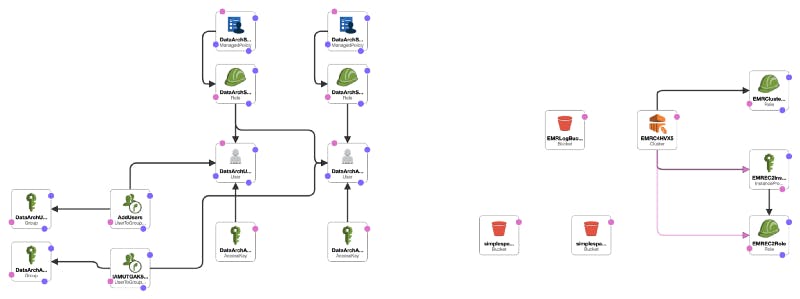
Fig. 1 — Cloudformation template
To create the Stack, I’ll follow these steps -
1. Navigate to Services > Compute > EC2 > Key pairs and create a Key Pair. Download the .pem file.
2. Navigate to the Cloudformation service from the AWS console
3. Open Cloudformation Designer (via the button ‘Design template’)
4. Open the template
5. Validate and Create the Stack
The template will output the KeyId and the SecretKey of the newly created IAM users, who will be named DataArchUser-* and DataArchAdmin-*.
Create Steps On the EMR Cluster
To create a Step on the cluster, I’ll navigate to Services > EMR > Clusters and add a Spark application step in the ‘Steps’ tab of my cluster.
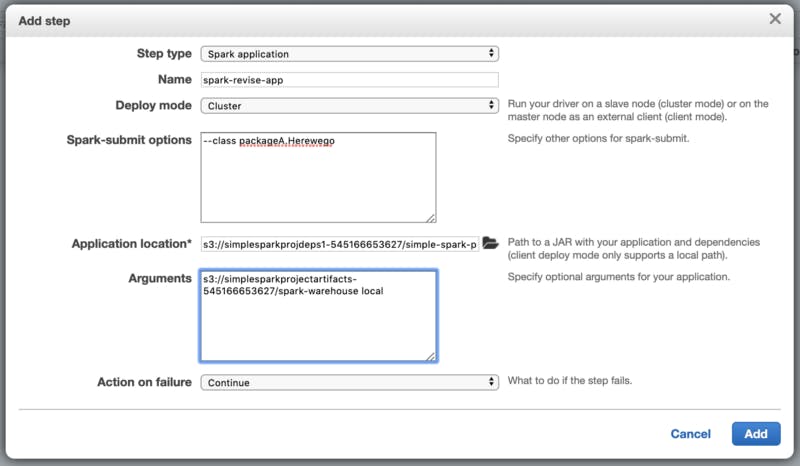
Fig. 2 — Step configuration to add Spark application
Check Output Hive External Table
Once the Spark app is completed, I can query the final Hive external table in Hue using HiveQL.
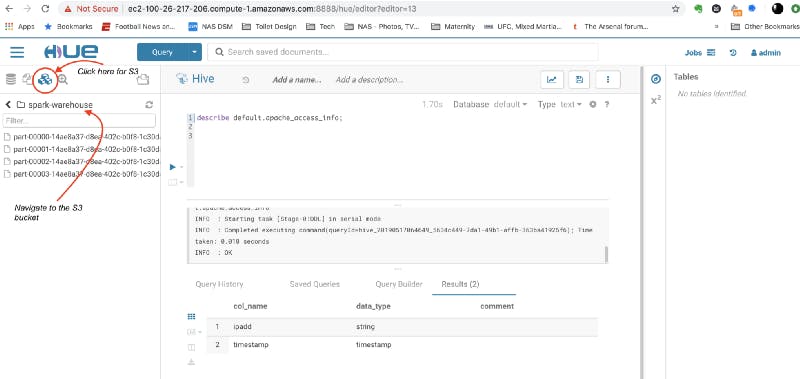
Fig. 3 — Querying the external table in Hive
And that’s it! I now have a working cluster that I can now use to develop and run more complex applications. This isn’t a production-grade cluster, but it is one you can quickly spin up to begin work on a new project.


