


How often have you cleared Jenkins accesses for your organization and make sure that it has been maintained properly?
When is the last time that you perform security patching your deployment pipelines?
How can you measure your DORA metrics? (What is DORA? An explorer? I’ll walk you through shortly in my next blog)
Imagine you are the head of DevOps team, looking after every CI/CD of 100 teams, deploying 200 products (or even 1,000) every single hour as a platform as a service provider. How can you make sure that at one point, servers running all your clients’ pipelines will not reach full capacity and block some features to reach their market in time?
And answer me this, how many DevOps engineer you can fish from the pool that is proficient enough in Groovy language nowadays?
Don’t get me wrong. As a Tech Lead of DevOps myself, I believe we could lay a foundation to protect the system from every angle, handcraft a Groovy file to store a chunk of reused codes and plugins, configure Jenkins with Kubernetes for scalability, guidance over the whole DevOps team for a deeper level of automation process whatever the tool we use ;)
But at what cost?
As a consultant, I’ve seen this transition trend of pipeline usage from heavily using Jenkins, a free and opensource tool. To these “Platform integrated pipeline” like, GitHub Actions, Gitlab CI, Bitbucket pipeline and so on.
Version Control — GitHub as we all know, is a famous repository provider, this epitome of source control provider won’t disappoint you in term of storing a declarative pipeline code as single source of truth that you could trace back or roll forward easily enough without any plugins or magic configuration needed in the process.
Insights — With the need to prove that what we’ve done really uplift our developer life. Or to find another weak (slow) spot that we should tackle next, we need a proper measurement. This type of pipeline can give us just that, an ability to connect and extract usage information from every angle of engagements the whole organization have with their pipelines. For example, PRs number, commits a day by project and so on. A bit of source code to convincing you here.
pipeline_meta=$(gh api \
-H "Accept: application/vnd.github+json" \
-H "X-GitHub-Api-Version: 2022-11-28" \
/repos/${CI_REPOSITORY_NAME}/actions/jobs/${CI_JOB_ID})
pipeline_list_meta=$(gh api \
-H "Accept: application/vnd.github+json" \
-H "X-GitHub-Api-Version: 2022-11-28" \
/repos/${CI_REPOSITORY_NAME}/actions/runs/${CI_RUN_ID}/jobs?filter=$(date --date="2 week ago" +'%Y-%m-%d'))
The data that you could grab from this could be…
echo "-------------------"
echo "DORA in 2w for Main pipeline:"
echo "-------------------"
echo "Count of failed jobs: $(echo "$pipeline_list_meta" | grep -o -i failure | wc -l)"
echo "Count of successful jobs: $(echo "$pipeline_list_meta" | grep -o -i success | wc -l)"
echo "Success Ratio (Success/Total): $(echo "$pipeline_list_meta" | grep -o -i success | wc -l)/$(echo "$pipeline_list_meta" | grep -o -i success | wc -l)+$(echo "$pipeline_list_meta" | grep -o -i failure | wc -l) = $(echo "scale=2; $(echo "$pipeline_list_meta" | grep -o -i success | wc -l)/($(echo "$pipeline_list_meta" | grep -o -i success | wc -l)+$(echo "$pipeline_list_meta" | grep -o -i failure | wc -l))" | bc)"
Try it at your own risk, a piece of code here is originally wrote by me for Gitlab CI. I’ve let GitHub Copilot translate it into GitHub API just to demonstrate the idea here. A beauty of using AI.
Security — A pipeline job has their own short-lived token to use that’s been generated according to a rule and permission we’ve set for at repository level, project level or organization level which will automatically expired and died with each runner. With this concept we didn’t really have to maintain a bunch of tokens to connect to some services as a static variable anymore. For example, you could prepare your Cloud IAM to exchange a short-lived token with a certain runner so the runner has an ability to deploy an application to only production environment and as soon as it done the current token will be gone.
Ecosystem — Do you remember the first time you want to use SonarQube on your pipeline so that you have some security scan for your source code? What if I say, GitHub already offered ready-to-use security solutions as a build-in like, Code scanning using CodeQL, Secret scanning, Dependency scanning. Basically, cover most of SAST (Static Application Security Testing) and if that is not enough, we can still grab famous security tools from GitHub Marketplace and get on with it in our pipeline. Those tools will also be maintained by the trusted organization as well
There’s a couple more reasons like, ease of use, scalability but I didn’t think the point is strong enough to address further if we compare them to the first 4 those I mentioned above.
Let’s say you are convincing to hop on the bus of GitHub Migration with me now. Before we can get started on a real thing, there’s a couple of preparation you would have to do:
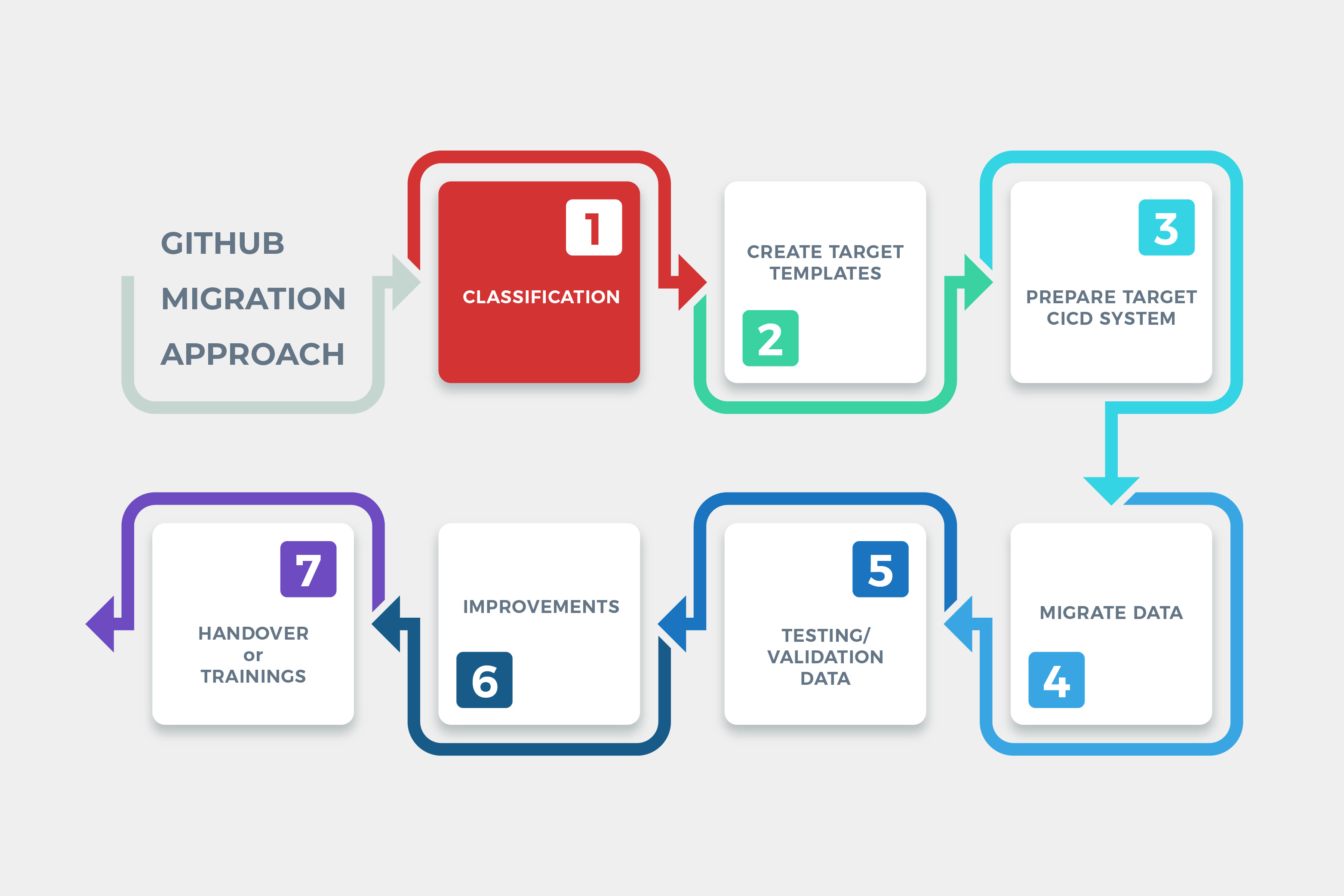
Classification Level 1 — I love to call this step “Prepare a convention”. This is where we identify current CI/CD environment from code to cloud, pipeline permissions and organization structure. To migrate to a certain pipeline integrated platform of your choice (in this case it’ll be GitHub). I highly recommend to first migrate the repositories. Didn’t mean that cross over between repository of this brand and a pipeline of that brand is not possible. It’s possible but don’t try. You’ll suffer and your security team won’t be happy. Trust me :\ (but yes, some brand is not even allowed it to happen). So, let’s consider these lists below
- Project and repository structure — GitHub repository only support flat repository structure unlike others. Naming convention could help to identify area of responsibilities and permissions later on
- User permission — GitHub has 5 pre-defined roles as a quick starter for any organization. Prepare a mapping between source and destination completely with a list of member email could help the migration and invitation sending, speed things up for adoption later
- Usage — In term of build times and scalability we need for the whole CI/CD of the organization
Classification Level 2 — Now we’ll look into deep detail of all repository and pipeline components those we are using right now which one you want to migrate and which one you don’t. As for repository, some could clone — mirror and some we have to build a copy and create script to automatically move them to destinate location. As for pipeline, GitHub even prepared a standard importer script for a famous brand, free of charge. What is a repository and pipeline component?
Repository related components
- Source code
- Commits
- Comments
- PRs
- Tags
- Issues
- Branchs
Pipeline related components
- Templates
- Third-party plugins
- Pipeline Runner specification
- Declarative pipeline scripts
- Non-declarative pipeline scripts (bash, shell you’ve been using on pipeline itself)
- Environment variables
- Secret variables
“I recommend doing repository classification and pipeline classification separately since the pipeline classification could get a helping hand from official GitHub Importer.”
As soon as we can identify all those components. Categorized it into baskets “Easy to script it away”, “Need a function to get it move”, “This one we need to map first”, “It starts to get complicated”
As for the pipeline or the workflow inside, some might need a revisiting of their life cycle — Not all current workflows will fit perfectly with new castle. For example, the connection with webhook, the API call to trigger chained pipeline. When you switch the target, it’s normal that you will have to change the endpoint to new destination or even change the method itself.
To be honest, classification here is the most crucial step of the whole GitHub migration plan. This is where all existing process will be clarified and concluded so that we can defined a migration strategy for each technical components and also planned a transition strategy for the whole organization. We are ready to give advice, analyze and strategically planning for those who interested in GitHub ecosystem adoption here at PALO IT THAILAND :)
As soon as all that is cleared. The next step will be “Create a migration script”
Which we will get back and continue in our next blog!


